Version Vectors
While studying dynamo db whitepaper, I read about this interesting topic called Version Vectors. This article is an attempt to explain the topic with examples along with associated pros and cons.
Problem
In a distributed system, when multiple servers accept writes for the same key, it could lead to concurrent writes, implying that there are 2 or more versions of data at that point of time.
Solution
Each key value is associated with a version vector that maintains a number for each cluster node.
In essence, a version vector is a set of counters, one for each node. A version vector for three nodes (blue, green, black) would look something like
[blue: 43, green: 54, black: 12]. Each time a node has an internal update, it updates its own counter, so an update in the green node would change the vector to[blue: 43, green: 55, black: 12]. Whenever two nodes communicate, they synchronize their vector stamps, allowing them to detect any simultaneous updates.
While comparing version vectors, we check the counter values against each node and if each of them is greater than or equal to their respective counterpart in the other vector, we can say that it occurred after and is not concurrent. If not, we say that the version vectors are concurrent. This table from Martin Fowler’s blog is quite useful.
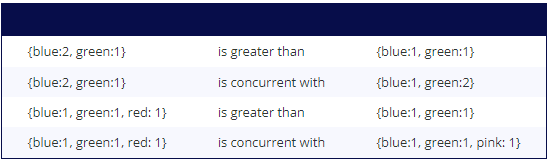
In case, there are nodes represented in a given VV and not other (example 3 and 4), we can assume that node’s counter in the other VV as 0. So, {"blue":1, "green":1} can be thought of as {"blue":1, "green": 1, "red": 0}, and {"blue":1, "green": 1, "pink": 1} as {"blue":1, "green": 1, "pink": 1, "red": 0}.
It is important to highlight that version vector is only incremented for the first cluster node the value is saved to. All the other nodes save the copy of the data.
Client IDs
In all the above examples, the version vectors used server ids to represent its internal state, however, there is also a variant of VV which use client ids. Using VV with CI, you don’t have any problem representing conflicts in the server, because each write is associated with the client that did it (one has as many IDs as the potential sources of concurrent writes). We can see that v3 correctly superseded v1, thus no false conflict occurred.
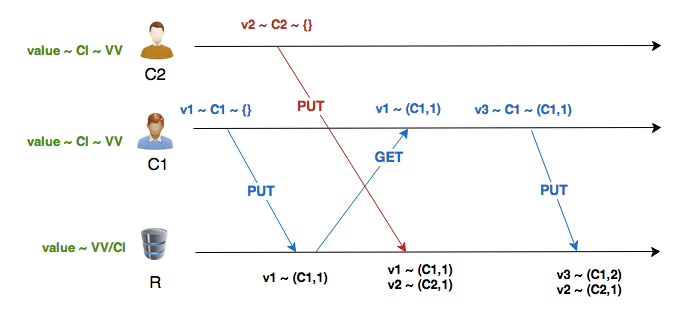
Problem:
Let’s say that there are 1000 clients, we will have to maintain 1000 (Client ID, Count) pairs for each key. We can prune older entries above a threshold, but that introduces further problems.
Example: VV1, arranged in order of update timestamps (latest to oldest) -
{"C1":4, "C2":2, "C3":5, "C4":2, "C5":1}
VV size limit is 4 and therefore, we drop C5 from the VV (C5 only present for representation). When C5 tries to update the key, it will find no values against C5 in the VV and set it to 1.
The new VV - {"C5":1, "C1":4, "C2":2, "C3":5}
This new write which is causally after VV1 will appear to be concurrent due to pruning.
Additionally, the same client could write to different servers and, if R/W quorum setup do not ensure read-your-writes session guarantees, each could end up with the same VV, although depicting different writes. For ex: Given two db servers S1 and S2 with empty VVs, when a client updates S1, its VV’ll be {"C1":1}. Before this update is replicated at S2, if the client (C1) reads from S2, it will start with an empty VV ({}) and on updating the value at S2, the VV’ll be {"C1":1}. Now, we have same VV on S1 and S2 with different writes.
Server IDs
The most common approach which is what we also discussed at the start is to use server ids to represent version vectors. In case of concurrent writes to different nodes, each node stores its update and increments the version vector.
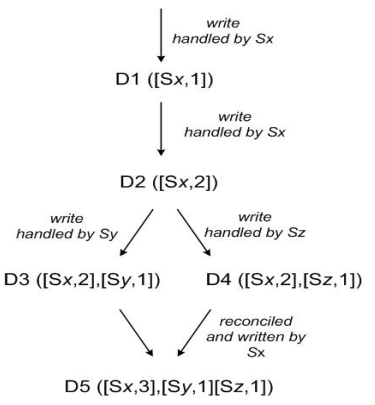
A client reads both D3 and D4 (the context will reflect that both values were found by the read). It will conclude using the version vectors that both the writes were concurrent. The client performs the reconciliation and node Sx coordinates the write, Sx will update its sequence number in the clock. The new data D5 will have the following clock: [(Sx, 3), (Sy, 1), (Sz, 1)]. For most systems, this solution’ll suffice, however, at AWS scale (thousands of servers), the size of vector clocks can become huge.
The dynamo paper recommends using a pruning scheme where older (node, counter) pairs are discarded once the no of pairs reaches a threshold. The effect is similar to what we observed with pruning in case of client ID based version vectors.
For ex, if the current VV is {"S1":4, "S2":2, "S3":5} and the threshold for pruning is 3. If the server “S4” accepts a write, the updated VV will be {"S4":1, "S1":4, "S2":2} (S3 is dropped due to pruning). The updated VV appears to be concurrent although it occurred causally after.
When there are concurrent writes to the same node, we can either reject an update indicating that the version is too old or we can accept both writes and store them for later reconciliation. However this approach can lead to sibling explosion.
{kind=link}
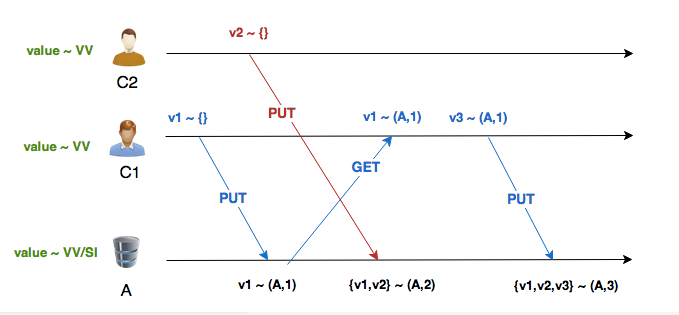
Problem: We lose the information that v1 was associated with (A,1) and not (A,2). In the third write we can see how this approach could lead to false conflicts. v3 is being written with (A,1), we know that it should win over v1 and conflict with v2, but since we lost information about the causal past of v1, the server has no other option but to keep all three values and merge the VV again.
To solve this problem, we use a variant of VV called dotted version vectors.
Using the context of last event
The novelty of DVV is to provide the context where the last event happened. To do that, we separate the last event from the VV itself. This last event is what we call the Dot (hence Dotted Version Vectors).
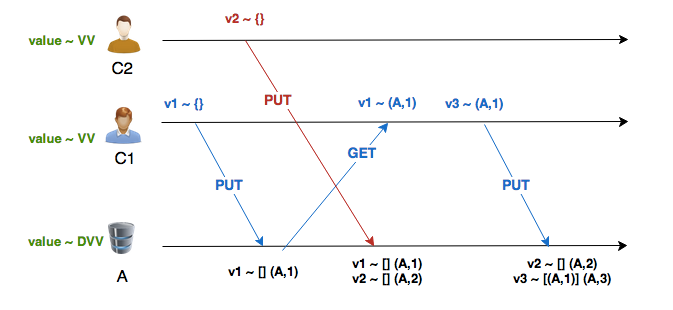
On the first write, since v1 had no causal context, the VV in the DVV is also empty. The Dot captures the last event, which in this case, is (A,1). When v2 is written, it also doesn’t have causal history, so the DVV also has a empty VV, but with the Dot (A,2), since its the second event recorded by A for this key. Both values coexist without confusion and preserve their context. Finally, when v3 arrives with the context (A,1), we know that it already read v1, thus it can be safely discarded. We keep v2 because it has events (updates) that v3 does not know. The DVV for v3 is the VV given by the client [(A,1)], and the Dot is the next available event by A : (A,3).
{kind=link}
The folks at Riak have a comprehensive article on Dotted Version Vectors. If you want to see an implementation, I highly recommend reading this github repo and its documentation. It covers advanced topics such as DVV sets (memory optimized version of DVV), pruning, anonymous list etc.