Oracle Indexes
Most developers prefer to use relational databases for their ACID guarantees. Relational databases are simple, optimized for reads (due to indexes) and suitable for majority of the projects. The other day I was working on a query to fetch data from an Oracle DB ordered by a few columns. Internet recommends using ORDER BY operation as data is not stored in any particular order in these tables (called heap-organized tables). For any dataset of reasonable size, this can consume significant compute resources (O (nlogn) operation). As developers, if we are clear of the requirements and conclude that we will use ORDER BY for majority of our queries in a given project, shouldn’t we be able to store data in that order in the disk itself? This question led me to deep-dive into an interesting category of tables, called Index-organized tables (IOTs).
But first, let’s understand INDEXES before proceeding to IOTs.
INDEX
Indexes are used to speed data access. In general, we consider using indexes in any of the following situation:
- The indexed columns are queried frequently and return a small percentage of the total number of rows in the table.
- A referential integrity constraint exists on the indexed column or columns. The index is a means to avoid a full table lock that would otherwise be required if you update the parent table primary key, merge into the parent table, or delete from the parent table.
- A unique key constraint will be placed on the table and you want to manually specify the index and all index options.
Indexes use a balanced BST (B-Tree) stored on disk to create a map between key (column on which index is created) and row id. Indexes can also be created on multiple columns, called composite indexes.
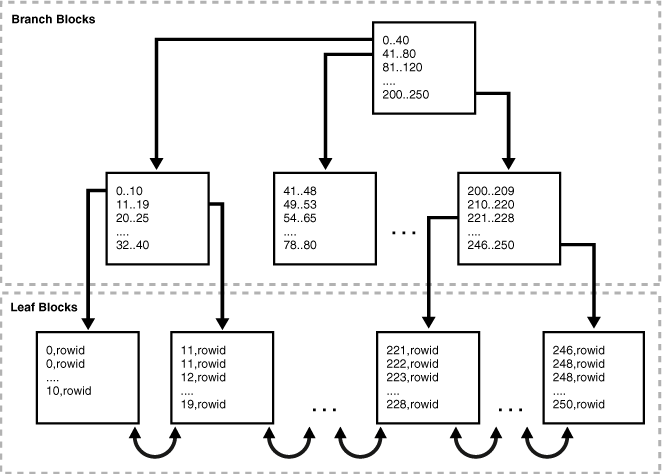
Types of index scans
In a full index scan, the database reads the entire index in order. A full index scan is available if a predicate (WHERE clause) in the SQL statement references a column in the index, and in some circumstances when no predicate is specified. A full scan can eliminate sorting because the data is ordered by index key.
Suppose that an application runs the following query:
SELECT department_id, last_name, salary
FROM employees
WHERE salary > 5000
ORDER BY department_id, last_name;
Also assume that department_id, last_name, and salary are a composite key in an index. Oracle Database performs a full scan of the index, reading it in sorted order (ordered by department ID and last name) and filtering on the salary attribute. In this way, the database scans a set of data smaller than the employees table, which contains more columns than are included in the query, and avoids sorting the data.
Clustering Factor
The clustering factor is useful as a rough measure of the number of I/Os required to read an entire table by means of an index:
- If the clustering factor is high, then Oracle Database performs a relatively high number of I/Os during a large index range scan. The index entries point to random table blocks, so the database may have to read and reread the same blocks over and over again to retrieve the data pointed to by the index.
- If the clustering factor is low, then Oracle Database performs a relatively low number of I/Os during a large index range scan. The index keys in a range tend to point to the same data block, so the database does not have to read and reread the same blocks over and over.
Index column key → row id (belonging to a data block). For a given index scan (range query), if the row ids are scattered across different data blocks, that increase I/O which will degrade performance.
Reverse Key Indexes
Reverse Key Indexes are designed to resolve a specific issue, that being index block contention. Monotonically increasing indexes, such as Primary Keys generated by a sequence, are especially prone to contention as all inserts need to access the maximum “right-most” leaf block. A Reverse Key Index simply takes the index column values and reverses them before inserting into the index. “Conceptually”, say the next generated ID is 123456, Oracle will reverse it to 654321 before inserting into the index. It will then take the next generated ID 123457 and reverse it to 754321 and insert it into the index and so on. By doing this, inserts are spread across the whole index structure, ensuring the right most block is no longer the only index leaf block being hammered.
One problem is the simple fact index entries are no longer sorted in their natural order. Value 123456 is no longer adjacent to value 123457 in the index structure, they’re likely to be found in completely different leaf blocks. Therefore a range predicate (such as BETWEEN 123450 and 123460) can no longer be found by a single index probe, Oracle would be forced to search for each specific index value separately as each value in the range is likely to be in differing leaf blocks.
How to decide order of columns in a concatenated, multi-column index? Conclusion is not what you think.
Index-organized tables
An index-organized table is a table stored in a variation of a B-tree index structure. In a heap-organized table, rows are inserted where they fit. In an index-organized table, rows are stored in an index defined on the primary key for the table. Each index entry in the B-tree also stores the non-key column values. Thus, the index is the data, and the data is the index. Applications manipulate index-organized tables just like heap-organized tables, using SQL statements.
The presence of non-keys columns of a row in the leaf block avoids an additional data block I/O.
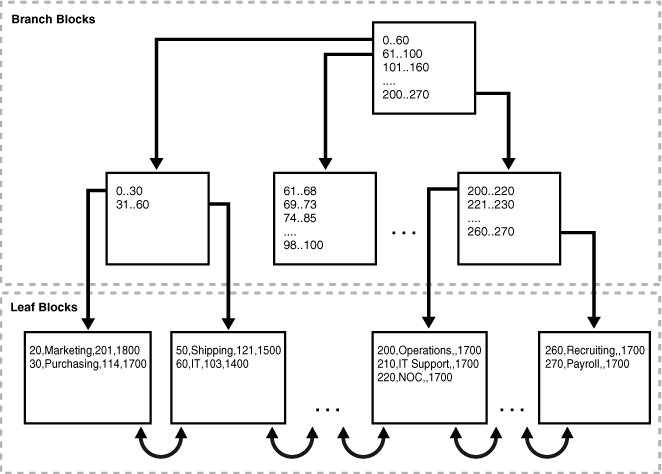
Reading data from index-organized table reduces data block I/O as closer items are stored together. However, in the case of a B-Tree, a scan of the table rows in primary key might returns row ids which are present in different data blocks.
Secondary indexes on index-organized table
A secondary index is an index on an index. Remember, in case of B-Tree, a secondary index stores column value and physical row id in the leaf blocks (use this row id to fetch the data block containing the row). However, in case of secondary indexes on IOT, we cannot use physical row ids to locate the row. Why? Firstly, there is no concept of physical row ids in IOT. Instead, we have logical row ids which are base-64 encoded representation of primary key. Secondly, row in leaf blocks of an IOT can move within or between blocks because of insertions (never a good idea to update primary key). As rows in IOT do not have a permanent physical location, we use logical row ids.
Logical Rowids and Physical Guesses
Secondary indexes use the logical rowids to locate table rows. A logical rowid includes a physical guess, which is the physical rowid of the index entry when it was first made. Oracle Database can use physical guesses to probe directly into the leaf block of the index-organized table, bypassing the primary key search. When the physical location of a row changes, the logical rowid remains valid even if it contains a physical guess that is stale.
For a heap-organized table, access by a secondary index involves a scan of the secondary index and an additional I/O to fetch the data block containing the row. For index-organized tables, access by a secondary index varies, depending on the use and accuracy of physical guesses:
- Without physical guesses, access involves two index scans: a scan of the secondary index followed by a scan of the primary key index.
- With physical guesses, access depends on their accuracy:
- With accurate physical guesses, access involves a secondary index scan and an additional I/O to fetch the data block containing the row.
- With inaccurate physical guesses, access involves a secondary index scan and an I/O to fetch the wrong data block (as indicated by the guess), followed by an index unique scan of the index organized table by primary key value.